Teaching AI to Read Movement Thoughts From EEG Using Video
Ziyuan Li, Yueyu Sun, Yimeng Zhang. “EVA-Net: Subject-Independent EEG Motor Decoding with Video-Derived Motor Priors.” arXiv:2606.01884. View Paper ↗
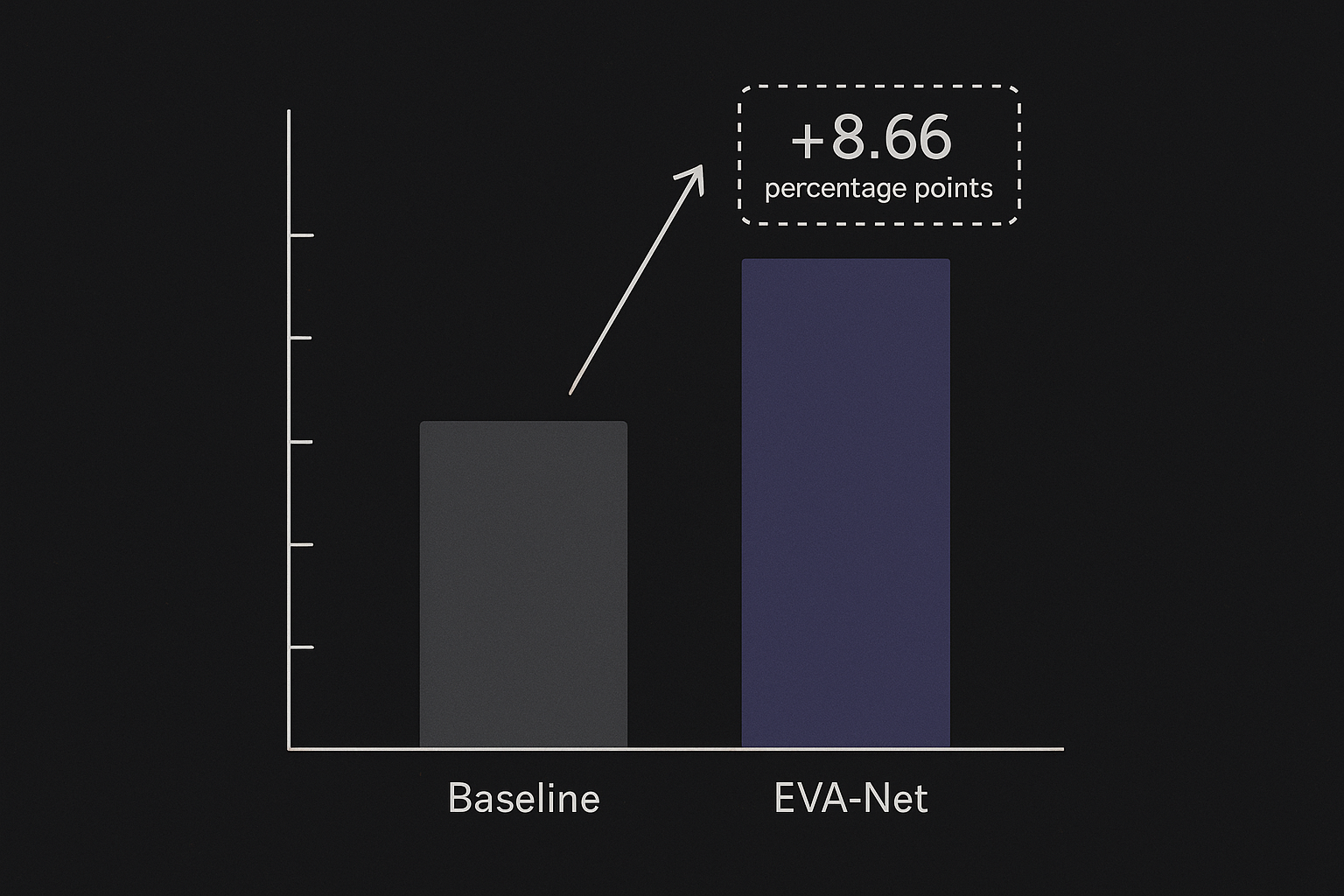
EVA-Net deciphers highly individualized motor imagery brainwaves without the need for calibration. It achieves this by utilizing action videos as semantic reference points, a novel approach compared to traditional word-based methods. This innovation led to a significant performance improvement, demonstrating an impressive 8.66 percentage point increase in Leave-One-Subject-Out (LOSO) accuracy on the EEGMMI dataset, outperforming text-based decoding methods.
Just Imagining Raising a Hand
Let's imagine for a moment, shall we? You, reading this very post, are mentally picturing yourself slowly raising your right hand, without actually moving a single finger. Your arm might be resting still on your desk, but in your mind, the movement of 'raising your right hand' is clearly unfolding. Fascinatingly, when we actually perform a movement and when we only imagine it, similar areas of the brain are activated. Scholars call this phenomenon motor imagery.
And it's precisely this phenomenon that serves as the starting point for technology straight out of science fiction movies: "controlling machines with just your thoughts." By imagining raising your hand, the brainwaves (EEG) at that moment can be read to move a robotic arm, a cursor, or even a wheelchair. We call this technology a Brain-Computer Interface (BCI).

However, there's a long-standing challenge here. Even when imagining the same 'raising your right hand' action, the pattern of brainwaves varies significantly from person to person. My brainwaves and yours are as unique as fingerprints. This meant that every time a new BCI device was used, a lengthy calibration process was required, collecting data by asking, "Now imagine your right hand," then "Now your left hand." The sheer inconvenience of this was one of the biggest reasons why BCI struggled to move beyond the lab.
To elaborate a bit more, when we wear new shoes, they might feel a bit uncomfortable at first, but after a few days, they break in and fit perfectly. Traditional BCI devices were similar. Every time they encountered a new user, they had to be 'broken in' for a considerable time to understand, "Ah, this person's brainwaves look like this." This 'breaking-in' period could range from tens of minutes to several visits. If you had to go through such a warm-up every time you wanted to use a device, no matter how good the technology, it would be too cumbersome for everyday use.
The EVA-Net research we're introducing today offers a highly creative solution to this very problem. Surprisingly, the key was "video." It transformed the method of teaching with words into teaching with living, moving scenes.
What Makes This Research Special
The title of this research is "EVA-Net: Subject-Independent EEG Motor Decoding with Video-Derived Motor Priors." To put it simply, it's a method for "decoding motor brainwaves, regardless of the person, by utilizing motor information derived from video." It was published by three researchers, Ziyuan Li, Yueyu Sun, and Yimeng Zhang, in June 2026.
For a BCI system to be practical, two things are essential. First, cross-subject generalization, meaning it works well for new, unseen users. Second, minimal calibration, offering convenience with little to no setup. However, as mentioned earlier, because brainwaves differ from person to person (inter-subject variability) and signals fluctuate over time even for the same person (signal non-stationarity), the "meaning of movement" and "a person's unique noise" become entangled. Untangling this mess is the core challenge.

Recently, researchers have tried to solve this problem by using "text" as a semantic anchor. For example, connecting words like "left hand" or "right hand" to brainwaves, thereby anchoring brainwaves to the stable meaning of a word. This idea was good, but it had limitations. Movement is fundamentally a dynamic process, but text can only provide sparse and static information. A single phrase like "raising your right hand" cannot capture the fluid, unfolding motion of an actual hand being raised.
This is where EVA-Net's insight shines. "What if moving video could best explain movement?" Instead of words, the researchers used action video as the semantic anchor. Videos of hands actually moving capture the temporal flow and rich information of that action perfectly. This is what makes this research special. They taught brainwaves the meaning of movement using living, moving videos as a "teacher," rather than static words.
How Was the Research Conducted?
EVA-Net has a clean, two-stage structure. To use an analogy, Stage 1 is "aligning at eye level," and Stage 2 is "standing on your own after graduation."
Stage 1: Aligning EEG and Video at Eye Level
In the first stage, EEG signals and action videos are aligned side-by-side in a shared space. Imagine two people speaking different languages opening the same map and agreeing, "This is the same place we're talking about." Features extracted from EEG and features extracted from video are trained so that similar actions are placed close together, and different actions are placed far apart.
Two contrastive learning objectives are used here. One is cross-modal alignment, which connects different types of data, and the other is supervised contrastive learning, which utilizes ground truth labels. The most significant effect of this process is reducing subject-specific variation. By aligning to a common reference point – the video – the individual noise of "whose brainwaves are these?" becomes blurred, and only the core meaning of "what action is this?" becomes clear.
Stage 2 — Standing on Its Own, Without a Video Teacher
In real-world BCI applications, only EEG signals are available. We can't feed in videos every time. So, in Stage 2, the knowledge acquired from videos in Stage 1 is transferred to an EEG-only classifier.
Two key mechanisms come into play here. One is video category prototypes, which serve as 'reference templates' representing each type of movement. The other is knowledge distillation, a well-known technique for compressing and transferring knowledge from a well-trained 'teacher' model to a 'student' model. Through these two mechanisms, video-derived priors (motor information extracted from videos) permeate into the EEG-only classifier.
The most exciting part is that this 'graduated' student model incurs no additional inference overhead at runtime. It only leverages video assistance during training, then operates as a lightweight and fast EEG-only model for practical use. It's like getting all the expensive tutoring during school and then walking into the exam hall with a light body and mind.
Key Findings
So, did this video-based approach actually work? The research team experimented with two public datasets and obtained significant results.
First, EVA-Net demonstrated robust performance in subject-independent decoding. Specifically, on the EEGMMI dataset, the LOSO accuracy improved by 8.66 percentage points. LOSO stands for Leave-One-Subject-Out, a method that rigorously measures generalization ability by completely excluding one subject's data from training and testing it as an 'unseen individual.' This means it was better at interpreting brainwaves from people it had never encountered before. This is precisely the 'works well without calibration' direction we've been aiming for.
Second, ablation study results suggested that video serves as a more effective semantic baseline than a text baseline. Ablation is a method to verify the contribution of each component by assessing 'how much performance drops if this part is removed.' In this case, comparing 'what if we use text instead of video?' favored the video approach. This confirmed the researchers' initial intuition: dynamic phenomena like movement are better represented by flowing videos than static words.
Third, as previously emphasized, all this performance was achieved without additional inference costs. Since heavy video models don't need to be run every time, it becomes much more feasible for deployment on practical devices.
To summarize: by teaching EEG the meaning of movement with rich video as a teacher (Stage 1), and then extracting and transferring that knowledge to a lightweight EEG model (Stage 2), a fast decoder was created that also works well for unseen individuals.
One point I'd like to emphasize is that all the numbers presented here are results actually reported in the paper. The '8.66 percentage point improvement,' the scope of 'two public datasets,' and the characteristic of 'no additional inference cost' are all facts verified by the researchers through experimentation. However, in this article, we've simply added analogies and everyday explanations to help your understanding. If you're curious about more detailed figures or experimental setups, we encourage you to consult the original paper (arXiv) linked below the article.
How Does This Impact My Life?
You might be thinking, 'Cool research, but it seems a bit distant from my daily life.' Surprisingly, the direction this research is heading is quite close to our everyday existence.
BCI technology has faced two main challenges: individual variability and the need for lengthy calibration every time. Consequently, BCI has largely remained confined to laboratories, hospitals, and specialized research environments. However, the advancement of technology that 'works well for unseen individuals without calibration' signals that such technology could someday transition into daily life without special training.
Imagine: someone with impaired hand function controlling devices with just their thoughts, providing accurate feedback in rehabilitation training by recognizing 'motor imagery,' or acting as a real-time mirror reflecting your brain state during meditation or focus training. The common foundation for these possibilities is 'EEG decoding that works lightly, without calibration, and transcends individual differences.' EVA-Net is a study that has solidified that foundation one step further.
Thinking about the field of rehabilitation, in particular, warms the heart even more. Did you know that individuals who find it difficult to move due to accidents or illness can reactivate their brain's motor areas simply by 'imagining movement'? If a machine could accurately discern whether 'the patient is truly imagining right-hand movement' and provide encouragement and feedback, the training's effectiveness would be significantly amplified. However, if each patient had to undergo lengthy and tiring calibration every time, those who need help the most would face the biggest barrier. This is why research that reduces the burden of calibration is so welcome.
Another noteworthy point is that this research highlights the importance of a 'good teacher.' Even with the same student (EEG model), proficiency varied depending on whether they learned from static textbooks (text) or vivid videos. Isn't this subtly relatable to us, who are constantly learning and acquiring new skills? It's similar to how, when learning foreign language vocabulary, seeing the word in context within a video stays in your memory much longer than just seeing the letters.
Furthermore, the direction of 'reducing the burden of calibration' is also a path towards making technology more equitably accessible to more people. The longer and more complex the calibration, the more likely it is that those who find the process difficult will be excluded from the benefits of the technology. Technology that works immediately for new users ultimately becomes technology for everyone.
Exploring with LINK BAND
Now, let's talk about LINK BAND. This research is more directly connected to LINK BAND than any other topic. That's because the signal EVA-Net deals with is precisely EEG, or brainwaves. LINK BAND 2.0 is a wearable that measures brainwaves (EEG), heart rate/blood flow changes (PPG), and movement (ACC). In that it measures EEG, the core ingredient of this research, in daily life, you could say they speak the same language.

However, there's something I absolutely, and honestly, want to state here. LINK BAND is not a clinical BCI controller for controlling machines with your thoughts. Things like 'moving a robotic arm with motor imagery,' as demonstrated by EVA-Net, fall within the realm of precise research and medical environments. LINK BAND is, first and foremost, a wearable designed to support daily wellness and research. It's more like a gentle mirror that reflects what rhythm your brainwaves are currently exhibiting, and where you stand between focus and relaxation.
Nevertheless, the message this research conveys to LINK BAND users is clear. As EEG decoding technology that 'works well without calibration, regardless of the person' advances, it lays the groundwork for everyday EEG devices like LINK BAND to become smarter and easier to use. We are, in essence, standing at the crossroads where today's lab achievements lead to tomorrow's wrist-worn experiences.
A Small Experiment You Can Try Today
Even without elaborate equipment, you can personally experience 'motor imagery,' the core theme of EVA-Net. Motor imagery practice is actually a well-validated method used in sports mental training and physical rehabilitation.
1. Sit comfortably and choose a single action. Something simple, like lifting a cup with your right hand, is ideal.
2. Close your eyes and 'play out' that action in your mind, like a video. Don't just think the words 'lift cup'; instead, visualize the entire flow, like a movie: your hand slowly extending, fingers wrapping around the cup, and lifting it. (This is the moment you physically grasp why EVA-Net chose video over text!)
3. Imagine the sensations too. Conjuring up the weight of the cup and the feel of it in your palm will make it even more vivid.
4. Repeat for 2-3 minutes a day, for a few days. As you repeat the same action, you'll notice the 'video' in your mind becoming increasingly clear and natural.
The key is to imagine it as a 'moving scene,' not 'static words.' Experience for yourself with this small experiment how flowing video is a richer teacher for our brains.
If you enjoy sports, it's also great to pick a favorite movement and repeatedly 'play back' the 'perfect execution' in your mind. Like the moment of a basketball free throw, the trajectory of a golf swing, or a single swimming stroke. Many athletes actually incorporate such imagery training as part of their regimen. It's a smart form of rest where the body relaxes, but the brain practices the movement. However, don't overexert yourself. Simply visualizing it lightly, with a relaxed mind, as if recalling a favorite movie scene, is enough.
Questions This Research Poses to You
EVA-Net took a significant step forward with an insight that, in hindsight, seems obvious but had not been deeply explored: 'the best teacher for movement is moving video.' When taught with vivid, flowing experiences instead of static words, the learner generalized more effectively.
So, finally, I want to leave you with a question.
When we learn and acquire new skills, are we perhaps relying too much on 'static words'? Are we fully utilizing 'flowing experiences' – by doing things ourselves and vividly visualizing scenes in our minds? And when the day comes that a small device on your wrist understands your brainwaves without calibration, what would you want to reflect in that mirror first?
LINK BAND Insight
EVA-Net directly addresses the type of electroencephalography (EEG) signals measured by devices like LINK BAND. As decoding technologies evolve to operate robustly across individuals and without extensive calibration, everyday EEG wearables, such as LINK BAND, are poised to become significantly smarter and more user-friendly.
Experience LINK BAND 2.0
Measure your brainwaves in real-time with integrated EEG, PPG, and ACC sensors. See for yourself what you read about today.
View Product→