영상으로 배운 AI가 '움직임 상상' 뇌파를 읽어낸다: EVA-Net 이야기
Ziyuan Li, Yueyu Sun, Yimeng Zhang. “EVA-Net: Subject-Independent EEG Motor Decoding with Video-Derived Motor Priors.” arXiv:2606.01884. 논문 보기 ↗
EVA-Net은 단어 대신 행동 영상을 의미적 기준점으로 삼아, 사람마다 제각각인 운동 상상 뇌파를 보정 없이 해독합니다. 텍스트 방식보다 뛰어났고, EEGMMI 데이터셋에서 LOSO 정확도가 무려 8.66%포인트나 올랐어요.
머릿속으로 손을 들었을 뿐인데
잠깐 상상해 볼까요? 지금 이 글을 읽고 계신 여러분이, 손가락 하나 까딱하지 않고 오른손을 천천히 들어 올리는 장면을 머릿속으로 그려본다고 해봐요. 실제로 팔은 책상 위에 가만히 놓여 있지만, 머릿속에서는 분명히 '오른손을 든다'는 움직임이 펼쳐지고 있죠. 신기하게도, 우리가 어떤 동작을 실제로 할 때와 상상만 할 때, 뇌에서는 비슷한 영역이 활성화됩니다. 이걸 학자들은 운동 상상(motor imagery)이라고 불러요.
그리고 바로 이 현상이, 공상과학 영화에서나 보던 "생각만으로 기계를 움직이는" 기술의 출발점이 됩니다. 머릿속으로 손을 드는 상상을 하면, 그 순간의 뇌파(EEG)를 읽어서 로봇 팔이나 커서, 휠체어를 움직이게 하는 거죠. 우리는 이런 기술을 뇌-컴퓨터 인터페이스(BCI, Brain-Computer Interface)라고 부릅니다.

그런데 여기엔 오래된 골칫거리가 하나 있습니다. 같은 "오른손 들기"를 상상해도, 사람마다 뇌파의 모양이 제각각이라는 점이에요. 제 뇌파와 여러분의 뇌파는 지문처럼 다릅니다. 그래서 BCI 기기를 새로 쓸 때마다 "이제 오른손을 상상해 보세요", "이번엔 왼손이요" 하며 한참 동안 데이터를 모으는 보정(calibration) 과정을 거쳐야 했죠. 이게 얼마나 번거로운지, BCI가 실험실 밖으로 나오기 어려운 가장 큰 이유 중 하나였습니다.
조금 더 풀어서 이야기해 볼게요. 우리가 새 신발을 신으면 처음엔 발이 좀 불편하다가, 며칠 신다 보면 발에 딱 맞게 길들여지죠. 기존 BCI 기기도 비슷했어요. 새 사용자를 만날 때마다 "이 사람의 뇌파는 이렇게 생겼구나" 하고 한참을 길들여야 했습니다. 그 길들이는 시간이 짧게는 수십 분, 길게는 몇 차례의 방문이 필요할 정도였죠. 매번 기기를 쓸 때마다 이런 준비 운동을 거쳐야 한다면, 아무리 좋은 기술이라도 일상에서 쓰기엔 너무 번거롭습니다.
오늘 소개할 연구 EVA-Net은 바로 이 문제에 아주 창의적인 답을 내놓습니다. 놀랍게도, 그 열쇠는 "영상"이었어요. 단어로 가르치던 방식을, 살아 움직이는 장면으로 바꿔본 것이죠.
이 연구가 특별한 이유
이 연구의 제목은 "EVA-Net: Subject-Independent EEG Motor Decoding with Video-Derived Motor Priors"입니다. 풀어 쓰면 "영상에서 끌어낸 운동 정보를 활용해, 사람에 상관없이 운동 뇌파를 해독하는 방법" 정도가 되겠네요. Ziyuan Li, Yueyu Sun, Yimeng Zhang 세 연구자가 2026년 6월에 공개했습니다.
실용적인 BCI 시스템이 되려면 두 가지가 꼭 필요합니다. 첫째, 처음 보는 사람에게도 잘 작동하는 일반화 능력(cross-subject generalization). 둘째, 보정이 거의 필요 없는 편리함(minimal calibration). 그런데 앞서 말했듯 사람마다 뇌파가 다르고(inter-subject variability), 같은 사람이라도 신호가 시간에 따라 출렁이기 때문에(signal non-stationarity), "움직임의 의미"와 "그 사람 고유의 잡음"이 뒤엉켜 버립니다. 이 엉킴을 풀어내는 게 핵심 과제죠.

최근 연구자들은 이 문제를 풀려고 "텍스트"를 의미의 기준점(semantic anchor)으로 써왔습니다. 예를 들어 "왼손", "오른손" 같은 단어를 뇌파와 연결해, 단어라는 안정적인 의미에 뇌파를 묶어두는 방식이죠. 아이디어는 좋지만 한계가 있었어요. 움직임이라는 건 본질적으로 역동적인 과정인데, 텍스트는 너무 드문드문하고(sparse) 정적인(static) 정보만 줄 수 있거든요. "오른손 들기"라는 단어 한 줄에는, 실제로 손이 올라가는 그 흐르는 듯한 움직임이 담기지 못합니다.
EVA-Net의 통찰이 바로 여기서 빛납니다. "움직임을 가장 잘 설명하는 건 움직이는 영상 아닐까?" 연구진은 단어 대신 행동 영상(action video)을 의미의 기준점으로 삼았습니다. 손이 실제로 움직이는 영상은, 그 동작의 시간적 흐름과 풍부한 정보를 고스란히 담고 있으니까요. 이게 이 연구가 특별한 이유입니다. 정적인 단어가 아니라 살아 움직이는 영상을 "선생님" 삼아 뇌파에게 움직임의 의미를 가르친 거죠.
연구는 어떻게 진행됐을까?
EVA-Net은 두 단계(two-stage)로 이루어진 깔끔한 구조입니다. 비유하자면, 1단계는 "눈높이 맞추기"이고 2단계는 "졸업 후 혼자 서기"예요.
1단계 — 뇌파와 영상의 눈높이 맞추기
첫 단계에서는 뇌파(EEG) 신호와 행동 영상을 같은 공간(shared space)에 나란히 정렬합니다. 서로 다른 언어를 쓰는 두 사람이 같은 지도를 펴놓고 "여기가 우리가 말하는 같은 장소야" 하고 합의하는 과정을 떠올려 보세요. 뇌파에서 뽑아낸 특징과 영상에서 뽑아낸 특징을, 같은 동작이면 가까이, 다른 동작이면 멀리 놓이도록 학습시킵니다.
이때 두 가지 대조 학습(contrastive) 목표를 씁니다. 하나는 서로 다른 종류의 데이터를 잇는 교차 모달(cross-modal) 정렬이고, 다른 하나는 정답 라벨을 활용하는 지도 대조(supervised contrastive) 학습이에요. 이 과정의 가장 중요한 효과는, 사람마다 다른 고유의 변동(subject-specific variation)을 줄여준다는 점입니다. 영상이라는 공통된 기준에 맞춰 정렬하다 보면, "이건 누구의 뇌파인가"라는 개인차 잡음은 흐려지고 "이건 무슨 동작인가"라는 핵심 의미만 또렷해지거든요.
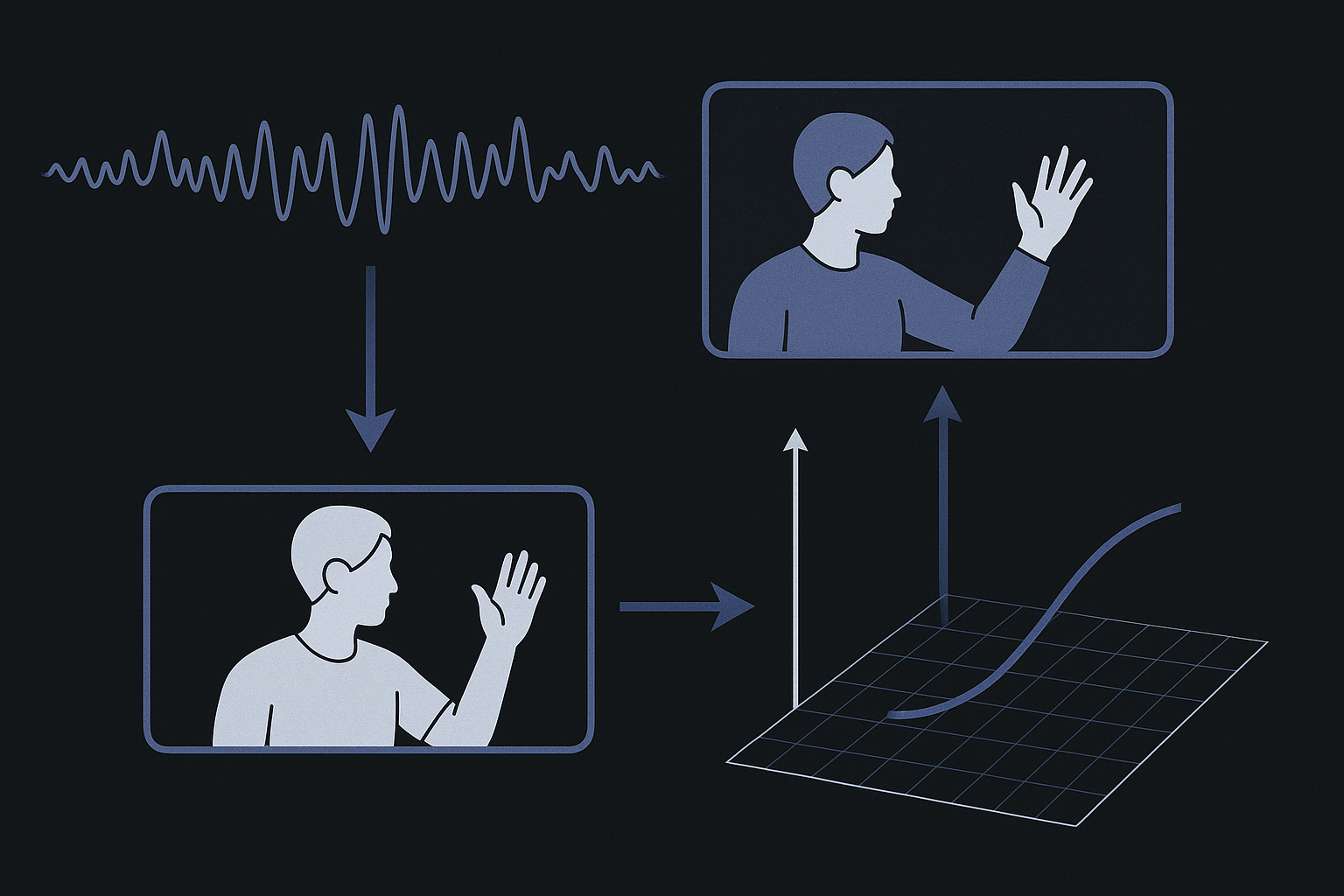
2단계 — 영상 선생님 없이도 혼자 서기
실제로 BCI를 쓸 때는 뇌파만 들어옵니다. 매번 영상까지 같이 넣을 수는 없죠. 그래서 2단계에서는 1단계에서 영상으로부터 배운 지식을, 뇌파만으로 동작하는 분류기(EEG-only classifier)에게 물려줍니다.
여기서 두 가지 장치가 등장해요. 하나는 영상 카테고리 프로토타입(video category prototypes)으로, 각 동작 유형을 대표하는 일종의 "기준 표본"입니다. 다른 하나는 지식 증류(knowledge distillation)인데, 잘 배운 선생님 모델의 지식을 학생 모델에게 압축해서 전수하는 잘 알려진 기법이죠. 이 두 장치를 통해 영상에서 끌어낸 운동 정보(video-derived priors)가 뇌파 전용 분류기 안으로 스며듭니다.
가장 멋진 부분은, 이렇게 졸업한 학생 모델은 추론 시점에 추가 부담이 전혀 없다(without adding inference overhead)는 점이에요. 학습할 때만 영상의 도움을 받고, 실제로 쓸 때는 가볍고 빠른 뇌파 전용 모델로 동작합니다. 비싼 과외는 학창 시절에 다 받아두고, 시험장에는 가뿐한 몸과 머리만 들고 가는 셈이죠.
핵심 발견
그래서 이 영상 기반 접근은 정말 효과가 있었을까요? 연구진은 두 개의 공개 데이터셋(two public datasets)으로 실험했고, 의미 있는 결과를 얻었습니다.
첫째, EVA-Net은 사람에 상관없이 동작하는 해독 성능(subject-independent decoding)에서 강력한 결과를 보였습니다. 특히 EEGMMI 데이터셋에서 LOSO 방식 정확도가 8.66%포인트 향상되었어요. 여기서 LOSO는 Leave-One-Subject-Out의 약자로, 한 사람의 데이터는 학습에서 완전히 빼두고 "처음 보는 사람"으로 테스트하는, 일반화 능력을 가장 정직하게 재는 방식입니다. 즉, 한 번도 본 적 없는 사람의 뇌파를 더 잘 읽어냈다는 뜻이죠. 바로 우리가 그토록 원하던 "보정 없이 잘 작동하는" 방향입니다.
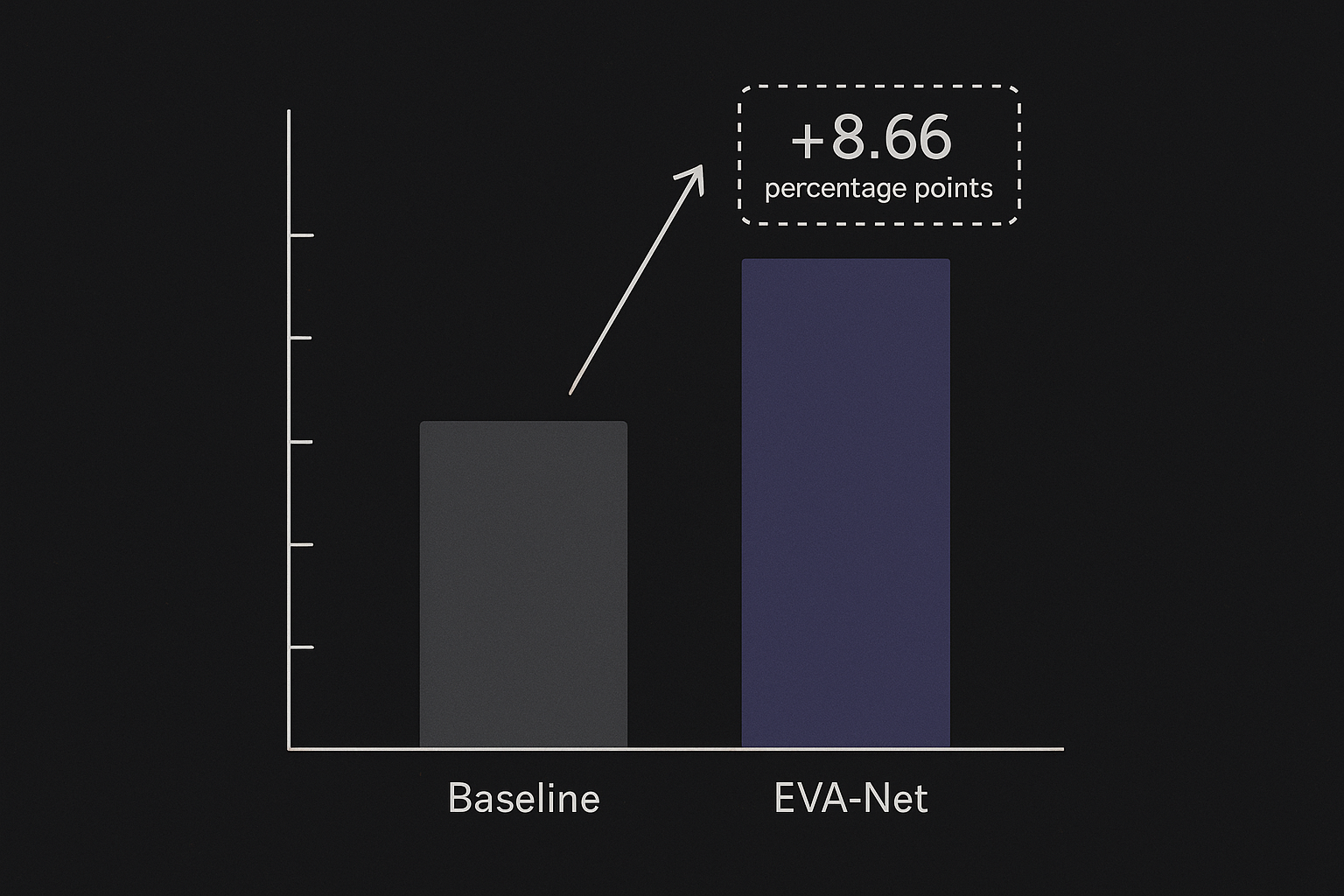
둘째, 어블레이션(ablation) 실험 결과는 영상이 텍스트 기준선(text baseline)보다 더 효과적인 의미의 기준점이라는 점을 시사했습니다. 어블레이션이란 "이 부품을 빼면 성능이 얼마나 떨어지나"를 따져보며 각 요소의 기여도를 검증하는 방법인데요, 여기서 "영상 대신 텍스트를 쓰면 어떨까?"를 비교했더니 영상 쪽 손을 들어준 거예요. 움직임이라는 역동적 현상에는 정적인 단어보다 흐르는 영상이 더 잘 어울린다는, 연구진의 처음 직관이 데이터로 뒷받침된 셈입니다.
셋째, 앞서 강조했듯 이 모든 성능을 추론 시 추가 비용 없이 달성했다는 점도 빼놓을 수 없습니다. 무거운 영상 모델을 매번 돌리지 않아도 되니, 실용적인 기기에 올리기 훨씬 좋아진 거죠.
정리하면 이렇습니다. 영상이라는 풍부한 선생님으로 뇌파에게 움직임의 의미를 가르치고(1단계), 그 지식만 쏙 뽑아 가벼운 뇌파 모델에게 물려준 결과(2단계), 처음 보는 사람에게도 잘 작동하면서 빠르기까지 한 해독기가 탄생했습니다.
한 가지 짚어두고 싶은 점은, 여기서 소개한 숫자들은 모두 이 논문이 실제로 보고한 결과라는 거예요. "8.66%포인트 향상"이라는 수치도, "두 개의 공개 데이터셋"이라는 범위도, "추론 시 추가 비용 없음"이라는 특성도 모두 연구진이 실험으로 확인한 사실입니다. 다만 이 글에서는 여러분의 이해를 돕기 위해 비유와 일상의 설명을 곁들였을 뿐이에요. 더 깊은 수치나 세부 실험 설정이 궁금하시다면, 글 아래에 연결된 원문(arXiv)을 직접 살펴보시길 권해 드립니다.
이게 내 삶과 무슨 상관이 있을까?
"멋진 연구네, 근데 나랑은 좀 멀어 보이는데?" 하실 수도 있어요. 그런데 이 연구가 향하는 방향은 의외로 우리 일상과 가깝습니다.
BCI 기술이 어려웠던 이유는 두 가지였죠. 사람마다 달라서, 그리고 매번 길게 보정해야 해서. 그래서 지금까지 BCI는 주로 실험실이나 병원, 전문 연구 환경에 머물러 있었습니다. 그런데 "처음 보는 사람에게도 보정 없이 잘 작동하는" 기술이 발전한다는 건, 언젠가 이런 기술이 특별한 훈련 없이도 일상으로 내려올 수 있다는 신호예요.
생각해 보세요. 손이 불편한 분이 생각만으로 기기를 조작하거나, 재활 훈련에서 "움직임 상상"을 정확히 인식해 피드백을 주거나, 명상이나 집중 훈련에서 내 뇌 상태를 실시간으로 비춰주는 거울이 되는 것. 이런 가능성의 공통 토대가 바로 "개인차를 넘어, 보정 없이, 가볍게 작동하는 뇌파 해독"입니다. EVA-Net은 그 토대를 한 칸 더 단단하게 다진 연구인 거죠.
특히 재활 분야를 떠올리면 마음이 더 따뜻해집니다. 사고나 질병으로 몸을 움직이기 어려워진 분들이 "움직임을 상상하는 것"만으로도 뇌의 운동 영역을 다시 활성화하는 훈련을 한다는 사실, 알고 계셨나요? 이때 "지금 환자분이 정말로 오른손 움직임을 상상하고 있는지"를 기계가 정확히 알아차려 격려와 피드백을 줄 수 있다면, 훈련의 효과는 훨씬 커질 거예요. 그런데 만약 환자마다 길고 지치는 보정을 매번 거쳐야 한다면, 정작 가장 도움이 필요한 분들이 가장 큰 장벽을 만나게 됩니다. 보정의 부담을 덜어주는 연구가 반가운 이유가 여기에 있어요.
또 하나 음미할 만한 점은, 이 연구가 "좋은 선생님"의 중요성을 보여준다는 거예요. 같은 학생(뇌파 모델)이라도 정적인 교재(텍스트)로 배우느냐, 생생한 영상으로 배우느냐에 따라 실력이 달라졌습니다. 무언가를 배우고 익히는 우리에게도 은근히 와닿는 이야기 아닌가요? 외국어 단어를 외울 때 글자만 보는 것보다, 그 단어가 쓰이는 장면을 영상으로 함께 볼 때 훨씬 오래 기억에 남는 것과 비슷한 이치입니다.
그리고 "보정의 부담을 덜어준다"는 방향은, 기술이 더 많은 사람에게 공평하게 닿는 길이기도 합니다. 보정이 길고 복잡할수록, 그 과정을 견디기 어려운 분들은 기술의 혜택에서 멀어지기 쉬우니까요. 처음 만나는 사람에게도 곧바로 잘 작동하는 기술은, 결국 더 많은 사람을 위한 기술이 됩니다.
LINK BAND로 살펴보기
자, 그럼 우리 LINK BAND 이야기를 해볼게요. 이 연구는 다른 어떤 주제보다 LINK BAND와 직접 맞닿아 있습니다. 왜냐하면 EVA-Net이 다루는 신호가 바로 EEG, 즉 뇌파이기 때문이에요. LINK BAND 2.0은 뇌파(EEG)와 함께 심박·혈류 변화(PPG), 그리고 움직임(ACC)까지 측정하는 웨어러블입니다. 이 연구의 핵심 재료인 뇌파를 일상에서 측정한다는 점에서, 같은 언어를 쓰는 사이라고 할 수 있죠.

다만 여기서 꼭, 그리고 솔직하게 말씀드리고 싶은 게 있어요. LINK BAND는 생각으로 기계를 조종하는 임상용 BCI 컨트롤러가 아닙니다. EVA-Net이 보여준 "운동 상상으로 로봇 팔 움직이기" 같은 건 정밀한 연구·의료 환경의 영역이에요. LINK BAND는 어디까지나 일상의 웰니스와 연구를 돕는 웨어러블입니다. 내 뇌파가 지금 어떤 리듬을 띠는지, 집중과 이완 사이 어디쯤 있는지를 부드럽게 비춰주는 거울에 가깝죠.
그래도 이 연구가 LINK BAND 사용자에게 주는 메시지는 분명합니다. "보정 없이, 사람에 상관없이 잘 작동하는" 뇌파 해독 기술이 발전할수록, LINK BAND 같은 일상용 뇌파 기기가 더 똑똑하고 더 쓰기 편해질 토대가 마련된다는 거예요. 오늘의 연구실 성과가, 내일의 손목 위 경험으로 이어지는 길목에 우리가 서 있는 셈입니다.
오늘부터 해볼 수 있는 작은 실험
거창한 장비 없이도, EVA-Net의 주제인 "운동 상상"을 여러분 스스로 체험해 볼 수 있어요. 운동 상상 연습은 실제로 운동 재활이나 스포츠 멘탈 트레이닝에서도 쓰이는, 꽤 검증된 방법이랍니다.
1. 편안히 앉아 한 가지 동작을 고르세요. 오른손으로 컵을 드는 동작처럼 단순한 게 좋아요.
2. 눈을 감고, 그 동작을 머릿속에서 "영상처럼" 재생해 보세요. 단어로 "컵 들기"라고 떠올리는 게 아니라, 손이 천천히 뻗고, 손가락이 컵을 감싸고, 들어 올려지는 그 흐름을 영화처럼 그려보는 거예요. (EVA-Net이 텍스트보다 영상을 선택한 이유를 몸으로 느껴보는 순간이죠!)
3. 느낌까지 상상해 보세요. 컵의 무게, 손바닥에 닿는 감촉까지 떠올리면 더 생생해집니다.
4. 하루 2~3분, 며칠 반복해 보세요. 같은 동작을 반복하면, 머릿속 "영상"이 점점 또렷하고 자연스러워지는 걸 느끼실 거예요.
포인트는 "정적인 단어"가 아니라 "움직이는 장면"으로 상상하는 것입니다. 우리 뇌에게도 흐르는 영상이 더 풍부한 선생님이라는 걸, 이 작은 실험으로 직접 경험해 보세요.
혹시 운동을 좋아하신다면, 좋아하는 동작 하나를 골라 "완벽한 한 번"을 머릿속에서 반복 재생해 보는 것도 좋아요. 농구 자유투를 던지는 순간, 골프 스윙의 궤적, 수영의 한 스트로크처럼요. 많은 운동선수들이 실제로 이런 이미지 트레이닝을 훈련의 일부로 삼습니다. 몸을 쉬게 하면서도 뇌는 그 동작을 연습하는, 똑똑한 휴식인 셈이죠. 다만 너무 애쓰지는 마세요. 편안한 마음으로, 마치 좋아하는 영화의 한 장면을 떠올리듯 가볍게 그려보는 것만으로 충분합니다.
이 연구가 당신에게 던지는 질문
EVA-Net은 "움직임을 가르치는 가장 좋은 선생님은 움직이는 영상"이라는, 어찌 보면 당연하지만 누구도 깊이 파고들지 않았던 통찰로 한 걸음을 내디뎠습니다. 정적인 단어 대신 생생한 흐름으로 가르칠 때, 배우는 쪽은 더 잘 일반화했죠.
그래서 마지막으로 여러분께 질문 하나를 남기고 싶어요. 우리는 무언가를 배우고 익힐 때, 혹시 너무 "정적인 단어"에만 기대고 있지는 않나요? 손으로 직접 해보고, 머릿속에서 생생한 장면으로 그려보는 "흐르는 경험"을, 우리는 충분히 활용하고 있을까요? 그리고 언젠가 여러분의 손목 위 작은 기기가 여러분의 뇌파를 보정 없이 이해해 주는 날이 온다면, 여러분은 그 거울에 무엇을 가장 먼저 비춰보고 싶으신가요?
LINK BAND 인사이트
EVA-Net은 LINK BAND가 측정하는 바로 그 뇌파(EEG)를 다룹니다. 보정 없이 사람에 상관없이 작동하는 해독 기술이 발전할수록, LINK BAND 같은 일상용 뇌파 웨어러블도 한층 더 똑똑하고 편리해질 거예요.